A Month Building the Nova Programming Language with Claude Code: Where Autonomous Agents Break
TL;DR: A month ago I started building my own programming language, Nova, with Claude Code. Right now I have a working compiler, around two thousand passing tests, and almost three hundred completed engineering plans — closed by agents end-to-end with minimal involvement from me. The workflow: I think through a plan for some new piece of language functionality together with the agents, polish the plan over a few iterations, the agents work through it, and I review the result. It works surprisingly well. But not everywhere, and not always the way you expect. This article is about where autonomous agents break and what discipline catches it.
Why this article
There are plenty of articles about AI coding, and most of them show something like “I built a todo app in an hour with Cursor.” That’s fine as a first taste, but it sidesteps the real question: what happens when the task is bigger than hello-world and runs over a long stretch of time?
Here’s my case — I’m writing a new programming language and a compiler for it. (The why is a separate story, but in short: I had the time, and this isn’t the first language I’ve built.) A month of work in, the repository is public and anyone can see what it looks like so far: github.com/nv-lang/nova. I’ll give an honest account of my experience: what comes out of it, where the autonomous agents worked, and where they slammed into a wall at full speed — and what I did about it.
If you’re trying to apply agents to large, multi-day tasks, this article is for you.
What I’m building — briefly
Nova is a programming language I’m building with the AI era in mind. The hypothesis is simple: when most code is written by LLMs, it makes sense for the language to push side effects into the types. Then a reviewer can see from the signature what a function actually does — without diving into the implementation or guessing from the name.
An example signature:
fn transfer(from AccountId, to AccountId, amount Money)
Db Fail[InsufficientFunds] Fail[InvalidAccount] Time Log
-> TransferReceipt
Reading this line, an LLM (and a human) understands: it touches the database, can raise two specific errors, reads the clock, writes to the log. In Java, Python, or Go none of this is in the type — you have to read the body, or the docs, or chase the call sites. An LLM in those spots guesses, with all the consequences that brings.
And here’s real Nova code — a piece of the UTF-8 implementation in StringBuilder from the standard library:
// Check buffer suffix. Slice-view + memcmp (zero-copy).
export fn StringBuilder @ends_with(suffix str) -> bool {
ro sbytes = suffix.as_bytes()
ro slen = sbytes.len()
ro blen = @buf.len()
slen <= blen && @buf[blen-slen..blen].compare(sbytes) == 0
}
// --- Mutating (-> @) ---
// Append a codepoint as UTF-8 (1-4 bytes). Fluent push chain.
export fn StringBuilder mut @append(c char) -> @ {
ro cp = c as int
if cp < 0x80 {
@buf.push(cp as u8)
} else if cp < 0x800 {
@buf.push((0xC0 | (cp >> 6)) as u8)
.push((0x80 | (cp & 0x3F)) as u8)
} else if cp < 0x10000 {
@buf.push((0xE0 | (cp >> 12)) as u8)
.push((0x80 | ((cp >> 6) & 0x3F)) as u8)
.push((0x80 | (cp & 0x3F)) as u8)
} else {
@buf.push((0xF0 | (cp >> 18)) as u8)
.push((0x80 | ((cp >> 12) & 0x3F)) as u8)
.push((0x80 | ((cp >> 6) & 0x3F)) as u8)
.push((0x80 | (cp & 0x3F)) as u8)
}
@
}
The idea isn’t unique, of course. Koka, Eff, and Effekt have existed for fifteen years. They’re academic and never reached production. Nova is an attempt to make a practical effect system with a standard library aimed at backend work, designed to be written alongside an LLM.
This article isn’t really about Nova. It’s about the methodology of building serious things with autonomous AI agents, where Nova is the concrete case I’m testing the approach on.
A month in: what came of it
In short, about a month from the first commit, and the result is something I honestly didn’t expect — the pace of work genuinely caught me off guard.
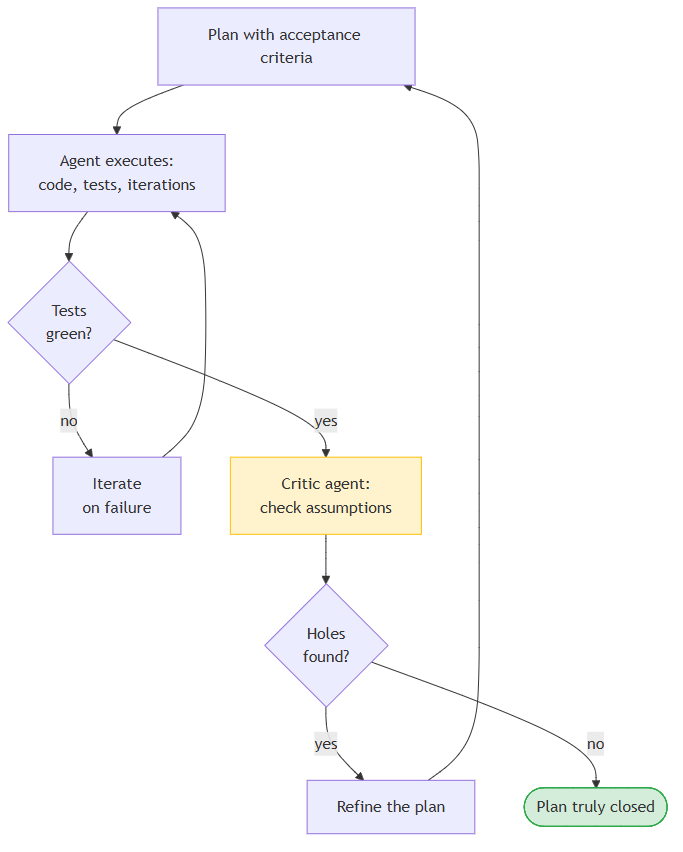
Around 300 plans closed by agents. Each plan is a structured markdown file of 500–2000 lines (they’re here): it says what we’re doing, what the acceptance criteria are, which tests must pass. The agent reads the plan and works through it on its own (writing the code), I review the result, discuss with the agent what simplifications were made and why, and if needed I tweak the plan and send the agent back for fixes. The process is iterative.
Tests for the Nova language have grown to almost two thousand (these are regression tests, so that what’s already implemented doesn’t break when something new is added). The agents run the regression suite after completing a plan, and it must pass in full. This is a hard rule: until it’s green, the plan isn’t closed — no “we’ll fix it later,” because there are so many plans in flight that anything skipped is quickly forgotten. The formal specification records nearly two hundred design decisions with rationale and context, worked out together with the agent during discussion.
What exists right now: a working compiler with C codegen (it generates C, which is then compiled by an ordinary cl.exe or clang — I consider this optimal at this stage of the language, because many bugs are caught by inspecting the generated C, which wouldn’t be possible if it emitted, say, binary directly). A runtime with a fiber scheduler, GC via Boehm (conservative, but it works), libuv for async I/O. The standard library is under active development. And on top of everything — an audit framework for the agents to check themselves, more on that below.
The Nova repository is open: github.com/nv-lang/nova, MIT license. You can clone it and run it.
Per day that works out to around eight to ten closed plans. One person physically cannot write that much code in that time. That’s the whole point of autonomy: I plan (together with an agent), the agent executes.
One important caveat about the setup. The plan itself — the design plus acceptance criteria — I write with an agent. After that comes autonomous execution by the agents: code, tests, iteration on errors, escalation if something goes off-plan. Quite often I can run agents in parallel on different parts of a plan, or simply on different plans. The finished result I review by hand against the criteria recorded in the plan. On average a plan is half an hour to a few hours of real agent work, my review is usually about ten minutes, sometimes longer if the result isn’t obvious. Sometimes it’s slow on both sides, but that’s the rough order. This doesn’t mean I work ten minutes and then sit idle — since I run many agents in parallel on different tasks, I’m constantly busy too. It’s like a conveyor belt: one plan goes into work, another finishes and needs review. The total volume of work that gets done is serious.
Where they break: four places
A month of intense work produced some statistics. What follows is four categories of failure that show up regularly. I’ll go through cases from the repo, my reaction, and my understanding of what’s happening.
Failure 1. Confident hallucinations
The nastiest one is confident hallucinations. The agent states something that simply isn’t true. A fact invented because “that’s usually how it is.”
One plan was about variadic parameters, an ordinary feature in languages: fn foo(...args []int). The agent did it, ran the tests, all green. Marked the plan closed; I skimmed the result and confirmed it too — looked correct. A few days later I was debugging something completely different and asked the agent to run the interpreter (one of the early execution modes of the compiler, which I’ve mostly abandoned since, because maintaining two execution channels at once costs too much) — and it silently produced seven failures out of seven. It took me a moment to realize these were the same tests that had already been “green.”
Here’s what had happened: under the hood Nova had two execution paths at the time (generate C, or run the Nova code as an interpreter) — and the variadics implementation in the interpreter simply wasn’t there. The agent had implemented it in only one half, ran the tests, saw all green, and considered the work done. From its point of view everything looked great.
This kind of error isn’t caught by tests, because the agent itself believes it checked everything. And I, trusting it, also don’t re-check by hand what the agent just checked. The result — you can miss non-obvious details. Now I run a separate audit on top of the plan. A different agent with a different system prompt, in the role of a critic. Its job is to look for gaps, shortcuts, and simplifications in the plan — anything that could in principle break but isn’t directly checked by tests.
On one plan about Nova’s contracts (they let you describe what a function requires and guarantees, and verify those claims at compile time via an SMT solver), this audit caught three critical correctness holes. Formally the code was proven correct, but under a certain combination of conditions the promise broke. For example, the verifier assumed numbers never overflow — but in the code an addition could overflow, so the “proof” was wrong. The loop analysis only saw plain x = e and skipped x += 1 and assignments inside if, so the invariant was “proven” against a stale value of the variable. And the third — the assume x > 0 operator, which was supposed to help the proof, wasn’t being passed through anywhere at all.
Without a separate critic those holes would have lived on in the project, and most likely I’d have found them only through an incident in production. Local errors AI catches well, better than a human; what slips through are systemic assumptions — the ones tests silently rest on. Here you can’t get by without a separate pass from a different angle. Ideally with a different model, or at least a very different prompt. For instance, I often added to the prompt: re-check from scratch such-and-such…
Failure 2. Defending the previous position
This one is subtler. The agent defends a design decision it proposed itself some time ago (days or weeks can pass). Even when new data clearly calls for a rethink. It resembles confirmation bias in humans, only sharper: a human at least has “okay, I overreacted,” whereas an agent will defend its position to the last.
I remember defending opt-in cycle collection. This was a feature where the programmer chose the memory-management prefix at the field-type level:
type Tree {
children []~Tree // Rc, real-time
parent ~weak Tree // weak reference
}
The idea offered a unique selling point — real-time guarantees at the level of the data structure. I believed in it at first too, or rather I didn’t object. The agent defended this feature against any doubt of mine, for weeks. It brought arguments about hot loops, embedded, audio. At times it even seemed to me that the agent itself was drawn to the idea of building a new programming language — that it had finally been chosen for a genuinely interesting and desirable task.
At some point I said a few words: “Kubernetes is written in Go” — meaning that the largest distributed system in the world runs on a language with a GC, and it doesn’t get in developers’ way. The agent pushed back at first: real-time matters, it’s a real niche for the language, don’t throw it away. I didn’t accept it. For another twenty minutes it kept producing arguments, but in the end it said something close to “yes, the argument is strong, I latched onto the real-time story because it sounds like a unique selling point for the language.” In the end we both agreed that a GC brings more upside than downside.
We rewrote two hundred lines of design. The prefixes went away, the default became managed memory with a modern garbage collector. Real-time wasn’t dropped entirely, but moved to opt-in via a region { ... } block for special zones where it’s genuinely needed: audio, trading, embedded.
What got us out of it in the end — you need an explicit devil’s advocate. That time I took the role myself; later I delegated it to a separate agent: one generates and defends the design, another is obliged to look for weak spots. The decision is always mine, but by the time I step in, the design has already been through opposition. Plus a set of pre-recorded principles, for example that “a feature blindly borrowed from another language must justify its existence.” In an argument with an agent such principles give you a point of leverage to return to when the logic spirals into something too elegant.
Failure 3. Beyond the familiar
A subtler case. The task looks typical, but it has one non-standard detail, and the agent doesn’t notice it. It works confidently from the usual template, and breaks on exactly that detail.
Plan 95 — rewrite five “pure” Option/Result methods from C trampolines into Nova code. Something like Option.unwrap_or(def) => match @ { Some(v) => v, None => def }. The task seemed simple, the agent did it, the tests passed. A day later I needed to come back to this code — and found that the C compiler was failing.
Technically, here’s what happened. For each use of a generic, Nova generates a separate C function with the type baked into the name — for example, Option_unwrap_or_int. In parallel, our runtime has old function names kept around via #define for backward compatibility. A couple of the newly generated names happened to collide with those old ones — the C compiler saw a duplicate symbol and failed.
I recorded the lesson not as a checklist item, but in the code generator itself: a generated function name now always carries the type suffix, even when it could formally be shorter. This rules out collisions with the #define aliases structurally, without having to remember “did I check this” every time. The principle going forward: if you find a detail the agent missed because it worked from the standard template, it’s better to lock it in with a hard rule in the code than to add “don’t forget to check this” to the plan template — an agent will eventually forget a checklist too, but a rule in the code won’t.
Failure 4. Echo chamber
A multi-agent setup should, in theory, catch errors better than a single agent. In practice, especially early on, it easily turns out the opposite.
My earliest setup was simple: a “builder” writes the code, a “reviewer” checks it. Correct in principle, but both used the same context and the same examples in the system prompt. The reviewer systematically approved the builder’s mistakes — they “looked right” by the very patterns it was tuned on.
Now there are several reviewer agents, and they appeared one at a time. First I added a separate fact-checker, with a maximally technical job: verify that the claims in an artifact actually match the state of the repository. It runs grep, looks at git log, actually runs nova test. That closed half the problems right away.
Then came the style checker — after a couple of incidents where code passed the tests but was written “out of keeping” with the project: error handling done its own way, odd module splits, idioms unfamiliar to neighbouring files. This agent compares against existing patterns in the codebase.
The adversarial agent came last, in two variations. The first is general — find the biggest hole in the artifact, a deliberately negative angle. The second is security-focused: memory problems and resource leaks, plus a separate focus on race conditions in concurrent code. I split them after the general adversarial agent kept systematically missing concurrency bugs; not its profile, its focus is on logic holes.
If even one of the reviewers flags a problem, the artifact comes to me for manual review and approval. Plus a sampling audit — I review around 5–7% of automatically executed operations per week myself, chosen at random. Not every one, but enough for a statistical signal: if the agents’ accuracy drops, I’ll notice.
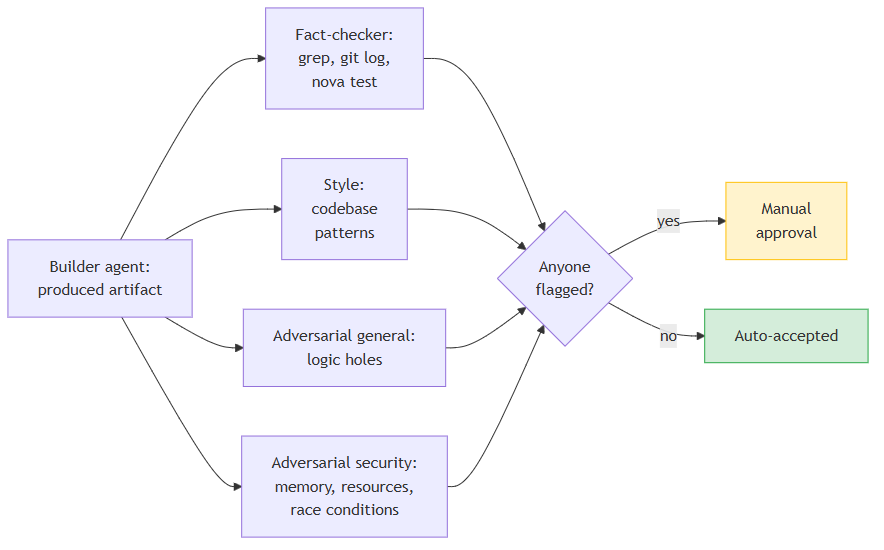
The number “four” here is incidental. If the classes of incident had fallen out differently, it would be three or five. The only thing that matters is that their angles are genuinely different. When I started out with a “builder” and a “reviewer” sharing one context, that was the same echo effect, just at a smaller scale.
What works, with discipline
The foundation of the whole scheme is the plan as a contract. A markdown file that both I and the agent read the same way, with acceptance criteria you can later check as “closed or not.” It’s an agreement between me and the agent on what counts as done. I call it a plan, though early on I called it different things — “spec,” “task,” “brief.” In the end “plan” stuck, because the word is a reminder to go through every point to the end, with no cheating via “that’ll do.”
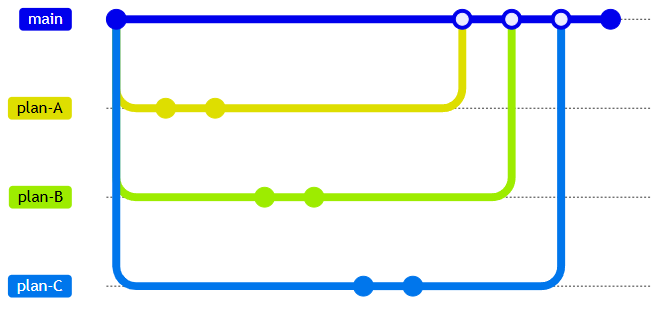
On top of the plan there’s isolation via worktrees. One task — one separate copy of the repository. The agent can’t accidentally break another line of work; it physically can’t see it. Conflicts, when they arise, are resolved by an ordinary git merge by the agents themselves. Before this I tried just using separate branches without worktrees for a while, and a couple of times an agent managed to start work in one branch, switch on my request, and leave dirty state behind that later surfaced in the most unexpected places. Worktrees killed that once and for all — recommended.
Next — the audit cycle I already described in Failure 1. Closing a plan doesn’t mean “accepted”: after closing there’s a separate critic pass looking for holes in the assumptions. Only then is a plan considered truly closed. Expensive in time, but cheaper than fixing two weeks later what leaked through. And agents, I’ll let you in on a secret, love to cut corners where they shouldn’t, love to simplify a task even when I explicitly ask them not to! They love skipping certain points of a plan, deeming them inessential for the current stage. So the audit cycle is simply mandatory.
And versioning prompts as code. The agents’ prompts and rules live in git and go through review like ordinary code; changes are tracked by diff. When the agents’ quality drops, you can figure out which patch broke it and roll it back.
Plus a few procedural things. A hard barrier of zero test regression after closing a plan: if a regression happened, the plan isn’t closed, it has to be fixed. Escalation by thresholds — the higher the stakes of a decision (say, legal consequences or a serious sum), the higher the escalation level to a human, and at the very top it’s me personally. For typical recurring situations there are pre-written rules of the form “if X, then Y.” Everything else comes to me.
From the outside this looks over-regimented, and at first I resisted it myself: it felt like I was burying myself in bureaucracy to compensate for distrust of the agents. But without this structure the pace of eight to ten plans a day simply doesn’t hold — everything starts to fall apart within two or three weeks.
What it costs and what it saves
So, money — what are the expenses? Claude Code cost me around twenty thousand rubles for the month. That’s the real operating cost. Add to that a decent computer with a fast disk so the agents can run builds in parallel — but that’s an investment, not a recurring expense.
Comparing it to engineering time is less direct. If I conservatively estimate that a single mid-to-senior engineer would do those same three hundred plans by hand, at around 4–6 hours of human time per plan on average, sometimes much more, that comes to roughly 1200–1800 hours of work. That’s about 7–11 months full-time for one person, if they’re lucky and free of distractions (and we both know they won’t be). For me — one month, one person, with agents.
Twenty thousand on an AI agent is tens of times less than the cost of an engineer’s work doing that same volume by hand — but the financial saving isn’t even the main thing here. What matters more is that one person manages a volume of work that would otherwise require a team. Without agents I’d never have pulled off a project of this scale solo, and the spend on the AI agent pays for itself many times over.
Where a human is genuinely needed
After a month it became fairly clear what doesn’t automate, no matter how much you want it to. The biggest things — strategic pivots like “shut down this direction” or “reposition to a different segment” — always stay with the human. The cost of a mistake in such decisions is too high, and there may be no precedent at all. An agent can give a recommendation, but the decision I make myself.
The project’s principles are also on me. Which features Nova doesn’t add, where it deliberately won’t go. That’s a matter of taste and vision, with no formal rule. Delegate it to an agent and you lose the authorship; the project turns into an averaged set of features just like everyone else’s.
Crisis decisions outside the rules — when a trigger isn’t covered by the decision tree, the agent has to stop and escalate. Improvisation in those cases is the most expensive mistake you can make in this scheme.
In volume this is around five to seven percent of the work, but almost all of the risk concentrates there. A bad strategic decision easily zeroes out the accumulated result. The decision stays with the human; you mustn’t set an agent loose here, the damage can be considerable.
Forecast
A year out, I’m betting on one of two scenarios. Either this methodology — plan as a contract, plus the audit cycle and escalation to a human by thresholds — becomes the norm in the industry, the way code review and CI/CD became the norm a decade ago. Right now the phrase “I delegated N engineering tasks to agents” sounds almost like a provocation; in a year it may be routine.
Or it turns out that today’s AI agents are a local maximum, and in a year or two something entirely different appears: more advanced architectures or a fundamentally new approach.
I’d put the odds of the second one as not small — things are moving too fast — but right now the first scenario is working, and quite well. Of course you get used to the good things fast: I already find myself wanting more speed from the agents, wanting automatic communication between agents in tools like Claude Code; I think we’re only at the beginning here. But languages that aren’t optimized for the AI era may start to lose ground in serious engineering.
What I’m offering
The repository is open: github.com/nv-lang/nova, MIT license. You can clone it, run it, and see how it’s built.
I plan to publish write-ups on AI-paired engineering and the development of Nova — real cases and interesting decisions made by the agents. You can subscribe at nv-lang.org/newsletter. No spam, no affiliate links, just what I personally found worth writing down.
If you’d like to take part — I need design critics (PL experts) and std-module developers; testers on real cases are always welcome too. Issues in the repo are open.
A question for the comments
If you have experience running LLM agents autonomously at a serious scale — tasks that take hours or days without your daily involvement — tell me what breaks for you and what works. I’m currently assembling a general picture of failures at scale; I found four categories, and I’m curious which ones you have.